
La prima versione di Arcadia, strutturata a Categorie-Gruppi-Proprietà, non permetteva di distinguere il "peso" relativo dei vari caratteri nella determinazione dei taxon. E' tuttavia sensato porsi la domanda: "Ma tutti i caratteri devono avere lo stesso peso nel determinare il riconoscimento di un taxon?" Facilmente ci si convince che no, che, in alcuni casi, alcuni caratteri possono essere più rilevanti di altri. Estremizzando: la distribuzione geografica di una specie, a parte il caso degli endemismi, è un carattere molto meno rilevante, nella diagnosi, della sua morfologia; e fra gli stessi caratteri morfologici, ce ne sono sicuramente di più stabili e quindi affidabili e di più variabili a livello intraspecifico, quindi non altrettanto utili per il riconoscimento. Il seguito dell'articolo spiega in che modo e per quali aspetti è stata implementata in Arcadia la Rilevanza dei caratteri.
Rilevanza a livello di Proprietà o di Gruppo
La prima domanda da porsi è: a quale livello occorre impostare il concetto della Rilevanza dei caratteri? Si sarebbe tentati di mettere in relazione la Rilevanza con le Proprietà. In realtà questa prima ipotesi non è la migliore (almeno per quanto riguarda la terminologia di Arcadia).
Di fatto sarebbe piuttosto antiintuitivo immaginare che, se un soggetto avesse "12 antennomeri" questo fatto potrebbe dare una Rilevanza del carattere pari a 10 mentre se ne avesse 11, questo potrebbe dare una rilevanza differente. Piuttosto sembra più corretto immaginare che il numero di antennomeri (nel nostro esempio) possa avere una rilevanza (espressa come 10, 20, o qualsiasi altra) e che questa rilevanza possa essere maggiore o minore rispetto ad altri caratteri come il colore (non il Colore bianco o il Colore Rosso in sé e così via), la forma, ecc.
Quindi il termine a cui applicare la Rilevanza è più correttamente il Gruppo, cioè l'insieme delle Proprietà valutabili mutuamente esclusive e attinenti a un unico aspetto della descrizione del taxon.
In che modo esprimere la Rilevanza dei caratteri
Il modo più immediato e significativo per esprimere la rilevanza è tramite un indice numerico. Questo numero viene utilizzato nel calcolo della probabilità di correlazione (vedi sotto per maggiori dettagli). Detto questo, non è evidente quale possa essere la scelta migliore per questi indici numerici, dato che, in ultima analisi, si tratta di indici che non possono rappresentare valori assoluti di correlazione, ma solo probabilità che una determinazione sia più accurata di un'altra.
In questo senso sarebbero possibili approcci fra loro molto differenti: si potrebbe pensare di graduare una scala con pochi valori fissi, come, ad esempio:
- 1 = Poco rilevante, 2 = Molto Rilevante, 3 = Fondamentale nella determinazione
- 1 = Poco rilevante, 2 = Rilevante, 8 = Molto rilevante, 16 = Fondamentale nella determinazione
- ecc.
In Arcadia è stata impostata una scala di numeri interi da 1 a 100. Questa scelta lascia aperta ogni possibilità di gestione, all'interno dei vincoli matematici dati dall'algoritmo di calcolo sotto rappresentato.
Rappresentazione della Rilevanza
La Rilevanza nella determinazione viene presentata all'utente in tre punti:
- Nella visione tabellare della chiave, a fianco a ogni Gruppo, viene indicato il peso che l'Editor ha attribuito al Gruppo stesso.
- Nella Determinazione del taxon, sopra ogni riquadro che racchiude le Proprietà riferite a uno stesso gruppo, oltre al nome del gruppo viene anche indicato "(Rilevanza: x)";
- Sempre nella Determinazione del taxon, una volta che sia stata selezionata una Chiave, il pulsante Schema permette di avere uno schema navigabile della Chiave stessa che, oltre a esporre link per accedere rapidamente ai gruppi e alle proprietà, riporta la Rilevanza per ogni gruppo indicato.
Utilizzo della Rilevanza nel calcolo della correlazione
Il calcolo della probabilità di correlazione è stato modificato, rendendo questo calcolo una sorta di media pesata. Più in particolare, il calcolo avviene in questi passaggi:
- Vengono estratti tutti i Taxon non esclusi dalle Proprietà selezionate. (Rispetto al non esclusi vs inclusi vedi qui).
- Dato l'insieme
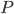 delle Proprietà selezionate, siano
delle Proprietà selezionate, siano 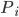 gli insiemi ottenuti togliendo, di volta in volta, un elemento da ; quindi se
gli insiemi ottenuti togliendo, di volta in volta, un elemento da ; quindi se 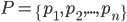 allora
allora 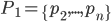 ,
, 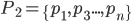 e così via.
e così via. - Per ogni insieme di Proprietà consideriamo l'insieme dei Taxon estratti; all'insieme di Proprietà corrisponderà l'insieme dei taxon estratti
 , vale a dire
, vale a dire 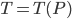 a corrisponderà
a corrisponderà 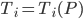 e così via...
e così via... - Ricordiamo però che ad ogni Proprietà
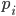 è associato un gruppo
è associato un gruppo 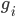 , al quale, a sua volta, è associato un indice di rilevanza:
, al quale, a sua volta, è associato un indice di rilevanza: 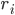 .
. - Contiamo quindi, considerando i taxon associati a come ai vari , il numero di occorrenze di ogni taxon
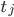 per un indice
per un indice 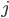 distinto da
distinto da 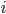 . Sia
. Sia 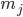 la molteplicità del taxon all'interno dell'insieme complessivo dei taxon estratti da e dai vari ; detto in altri termini: dato l'insieme delle Proprietà selezionate, se valuto quante volte compare il taxon in e in tutti i , questo numero sarà
la molteplicità del taxon all'interno dell'insieme complessivo dei taxon estratti da e dai vari ; detto in altri termini: dato l'insieme delle Proprietà selezionate, se valuto quante volte compare il taxon in e in tutti i , questo numero sarà - Prima dell'introduzione del concetto di Rilevanza del gruppo, la formula che portava a calcolare la correlazione poteva essere espressa come:
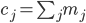 ; con l'introduzione della Rilevanza, la formula diventa
; con l'introduzione della Rilevanza, la formula diventa 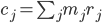 . Questo significa: la probabilità di correlazione del taxon rispetto all'insieme di Proprietà selezionate è data da
. Questo significa: la probabilità di correlazione del taxon rispetto all'insieme di Proprietà selezionate è data da 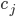 .
.
Normalizzazione dei valori
Dato che l'informazione estratta dal calcolo è di tipo statistico e comparativo (cioè "un valore è più strettamente correlato di un altro", non "taxon è esattamente 4,7 volte più correlato di un altro"...), il valore ottenuto di per sé dice poco. In un caso potrei ottenere 15, nell'altro 750, e così via. Per permettere una facile interpretazione dei dati estratti, questi valori vengono normalizzati, cioè ricalcolati in funzione di un valore massimo fissato. In particolare, la regola applicata è la seguente:
- Se l'insieme (dei taxon che corrispondono a tutte le scelte impostate) è vuoto, allora, per rappresentare il fatto che il match è solo parziale ("Nessun taxon corrisponde a tutte le scelte"), viene posto il punteggio massimo uguale a 80 e gli altri vengono calcolati in modo proporzionale.
- Se l'insieme non è vuoto, per identificare che almeno un taxon corrisponde completamente alle scelte, viene posto il punteggio massimo uguale a 100 e gli altri vengono calcolati in modo proporzionale.