
In Arcadia ci sono due motori di determinazione dei taxon: Inclusione/Esclusione e Probabilità di Correlazione. La ragione di queste due differenti implementazioni riguarda il fatto che, quando si impostano determinate scelte, una certa dose di approssimazione e di errore è comunque sempre possibile.
Il primo motore (Inclusione/Esclusione), più rapido nell'esecuzione, fornisce semplicemente una lista di possibili match. Tuttavia con questa modalità non è possibile vedere quali altri taxon rimangono esclusi, magari in base a una sola Proprietà.
Se la lista estratta non fosse quindi soddisfacente, è possibile ricorrere al secondo motore (Probabilità di Correlazione) che, oltre a mostrare gli esclusi, li ordina in funzione della Probabilità di correlazione decrescente, per fornire ulteriori "ipotesi alternative".
Di seguito vengono forniti maggiori dettagli tecnici relativi agli algoritmi implementati.
Inclusione ed Esclusione
L'algoritmo di Inclusione ed Esclusione è costituito dai passi seguenti:
- Vengono rilevate tutte le Proprietà selezionate.
- Per ogni Proprietà, all'interno del Gruppo di appartenenza vengono estratte tutte le altre Proprietà (Proprietà Escludenti). Il fatto che un Taxon sia associato a una di queste Proprietà implica che non possa essere estratto nella lista finale dei candidati per la determinazione.
- Vengono quindi estratti tutti i Taxon associati a queste Proprietà Escludenti, che costituiscono la lista dei Taxon che godono di "almeno una Proprietà" che porta ad escluderli.
- Per ogni Proprietà selezionata si ripetono i passi seguenti fino ad avere (unendo le varie liste) la lista completa dei taxon che hanno almeno una Proprietà che li porta ad essere esclusi in base alle scelte dell'utente.
- L'estrazione finale è data da tutti i taxon censiti nella chiave, meno i taxon della lista degli esclusi.
Probabilità di Correlazione
L'algoritmo che calcola la Probabilità di correlazione è costituito semplicemente da un certo numero di iterazioni dell'algoritmo precedente. Più in particolare, il funzionamento del secondo algoritmo è il seguente:
- Consideriamo la lista delle Proprietà scelte dall'utente:
 ; consideriamo che questo insieme abbia
; consideriamo che questo insieme abbia 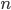 elementi.
elementi. - Consideriamo gli ulteriori insiemi ottenuti a partire da
 e rimuovendo ogni volta una Proprietà. La logica di questo passo può essere espressa come segue: "Oltre a considerare tutte le scelte effettuate, consideriamo anche di allargare la lista includendo tutti i Taxon che sono stati esclusi per una sola scelta".
e rimuovendo ogni volta una Proprietà. La logica di questo passo può essere espressa come segue: "Oltre a considerare tutte le scelte effettuate, consideriamo anche di allargare la lista includendo tutti i Taxon che sono stati esclusi per una sola scelta". - Otteniamo quindi, in aggiunta a
 anche gli ulteriori insiemi di scelte:
anche gli ulteriori insiemi di scelte:  ,
,  , eccetera.
, eccetera. - Applichiamo l'algoritmo di Inclusione ed Esclusione a e a tutti gli
 ; ogni volta otterremo una lista di Taxon estratti.
; ogni volta otterremo una lista di Taxon estratti. - Uniamo tutte queste liste e consideriamo quante volte compare il singolo Taxon. Chiaramente se un Taxon compare molte volte, a livello intuitivo, significa che anche rimuovendo una scelta rimangono comunque altre scelte che portano a considerarlo. All'altro capo un Taxon che compare poche volte sarà un Taxon con minori probabilità di correlazione.
- L'ultimo passo è quindi esporre la lista de Taxon considerati, riportando prima quelli che compaiono "più volte" e dopo quelli che compaiono "meno volte", dando per acquisito che maggiore è il numero di occorrenze di un Taxon all'interno di questa unione di insieme e maggiore sarà la probabilità di correlazione.
Considerazioni ulteriori
Per comprendere meglio sia la determinazione dei taxon, sia il funzionamento dei due motori di ricerca, potrebbe essere utile valutare anche le considerazioni seguenti:
- Se un Taxon, in un Gruppo, non è associato a nessuna Proprietà, questo implica che, qualsiasi scelta venga fatta in quel Gruppo, il Taxon non potrà essere escluso e quindi comparirà, a meno di altre esclusioni, nella lista finale.
- I "punti di correlazione" espressi nella lista estratta dall'algoritmo di Probabilità di Correlazione non hanno un valore quantitativo ma solo "qualitativo" in funzione dell'ordinamento decrescente. Vale il concetto: "Questo taxon ma maggiori probabilità di correlazione di quest'altro riportato con meno punti" ma non vale il concetto: "Se questo Taxon ha 40 pt di correlazione e quell'altro ne ha 20, allora questo ha il doppio delle probabilità di correlazione."